Linked Open Municipal Budget Data for Austria
Hi there!
You maybe wonder, what's this all about? In a nutshell, this project web site provides a comprehensible RDF vocabulary
for budget data from Austrian municipalities and exemplary Linked Data based on it.
RDF? Linked Data? Municipal budgets?
Hm... You got confused. I understand.
Linked Open Municipal Budget Data for Austria
Welcome!
On this as well as all other pages of this project’s website, you will find information about a vocabulary and respective data for local government finances in Austria, based on so-called “Linked Open Data”. The used approach and its technologies combine state-of-the-art and current best practices in this field of Information Science. This website and its application was conceptualised, developed and published originally in the year 2017 as part of a Diploma Thesis in Business Informatics at the Faculty of Informatics of the Vienna University of Technology. You can learn more about this work as well as the overall, pioneering concept of so-called “Linked Open Budget Data” on this very website. Read and study the given data to get a glimpse into the World Wide Web’s future, building not only a Web of Documents, but also a real Web of Data...
Technical overview
Not until the recent technical developments and progresses with respect to information technologies, the possibilities but also the needs to gain budgetary transparency of governmental finances are greater than ever. The goal to publish information about budgets of governmental authorities in a reasonable, comprehensive, transparent and open way induces challenges not only with respect to the data itself but also to the embedded budgetary processes and systems.
The approach presented and implemented on this project’s website and its application expands state-of-the-art approaches and
international best practices regarding Open and Linked Data towards
local government finances in Austria for generating a new level of best practise and transparency compared to
the status quo in this part of the world.
In the following, the overall concepts of these three elements used for this project shall be discussed in a nutshell. For more information, please have a
look into the underlying Diploma Thesis, which is the primary origin of this website and the following texts after all.
Local Government Finances
This project’s domain is about local government finances or – to be more precise – the budgetary data of Austrian municipalities. Public finances are – of course – a complex and wide-spread theme. However, in its core (relevant for this project) it is about all revenues and expenditures made by public bodies or, in case of this project, Austrian municipalities. The relevant legislation for this topic is the so-called “Voranschlags- und Rechnungsabschlussverordnung” (VRV) or Budgeting and Accounts regulation. There exist two relevant versions of this regulation nowadays: the VRV 1997, still applicable to today’s budgetary documents of Austrian municipalities, and the VRV 2015, which will become mandatory by no later than 2020. Both regulations require all Austrian municipalities to publish two budgetary documents, part of the overall so-called “budget cycle” depicted below and relevant for this project: budgets and statements of account.
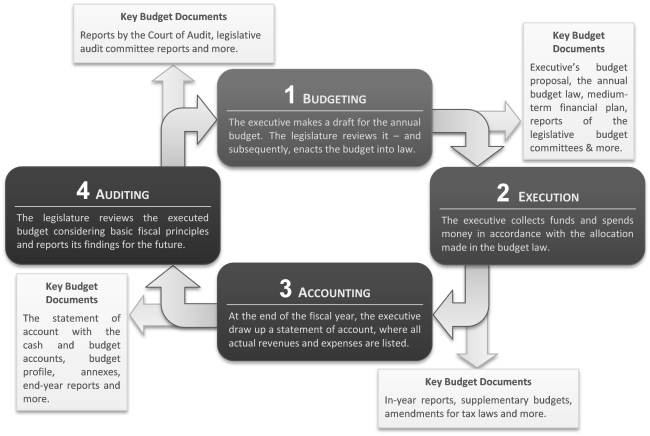
A budget is a report about a financial plan, where scheduled projects are depicted with all of their financial consequences. The budget is usually made in the first step of the budget cycle and prior to the applying fiscal period. In contrast, a statement of account – under the terms of the VRV – is a report about the realisation of a financial plan, whether and to what extent a municipality has performed its duties in accordance with the preliminary budget.
In order to be able to compare municipal budgets in the first place, all local government finances need to be classified according to the VRV. This is done in a functional and an economic as well as a fiscal way – resulting in a (at least) 7 digit long code associated with each cash flow in a municipal budget:

These codes as well as respective data associated with them are implemented by this project as Linked Data: the respective definition of these code lists are defined as Linked Data here for the fiscal classification, here for the functional one and, last but not least, here for the economic one.
In the end, the VRV also regulates a segment of all budgets and statements of account necessary for gaining a general overview about a municipal budget: the so-called “Rechnungsquerschnitt” or budget profile. This important part of local government finances’ statistics was also implemented based on Linked Data in the course of this project and various such budget profiles can be queried on another page of this website.
↿ Back to top ↾Linked Data
As complex as this project’s domain with local government finances can get as diverse its underlying technical concept with so-called “Linked Data” may prove. If you want to understand this innovative technologic principle used by this project, this section of this website shall be considered carefully.
In general, down to the present day most of the data distributed via the World Wide Web is “just” a Web of Documents or, to be more precise, Hypertext. However, as such hypertexts concentrate on human-readable, eponymous texts instead of actual data, this data is still often published in Documents on the Web (instead of in a Web of Data) – like Austrian budgetary data in PDF files or Microsoft Excel spreadsheets. Linked Data should provide such a Web of Data in addition to the current Web of Documents. The actual aim of Linked Data is to overcome issues by former data storage & distribution techniques: Today, in most cases, data is associated and, thereby, incorporated by specific applications. Metadata and data schema information are incorporated as such by those applications, instead of being separated from the actual application logic. A database or an export of its data is built specifically for certain applications, usually. For example, column headings in the ubiquitous CSV format are not really immediately useful, as the actual meaning of those textual designators is ambiguous and can differ from document to document. Furthermore, while looking at such a CSV file, humans may be able to derive some value from those column headings; a program, which is not explicitly built for this respective data schema, is not necessarily able to do so. That’s why in the end, Documents on the Web including their incorporated data are not (easily) reusable or even machine readable for third-party programs. In contrast to that, Linked Data – composing a Web of Data – is. Therefore, Linked Data becomes increasingly important when it comes to distributing data in an open way.
To understand Linked Data in its entirety, it is necessary to understand the related term of the “Semantic Web” as well. The Semantic Web can be understood as the effort to give the information (and the data) on the World Wide Web self-defined semantics and meaning. The idea is explicitly not to replace all current websites (and/or the data on them), but to enrich or extend them in a way, so that (especially automated) information retrieval is simplified.
The Semantic Web itself is made up by various technological standards also providing the foundation of its sibling “Linked Data”. These standards are commonly associated to several conceptual layers – each layer basing upon its underlying counterpart. This layer model illustrating the conceptual architecture of the Semantic Web is nowadays known as “Semantic Web Layer Cake” and is depicted below including exemplary technologies for the different layers, which – for the sake of simplicity – match those used for Linked Data in this very project.
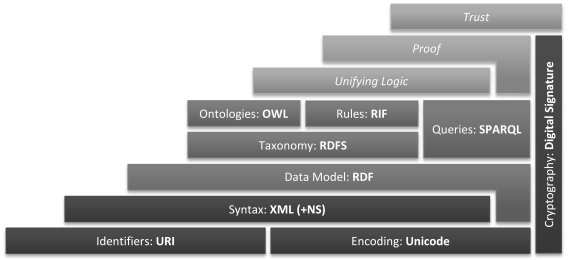
Linked Data is composed mainly by the lower and intermediate layers of this “Semantic Web Layer Cake”. Although no deeper explanation is given here on the respective technologies (feel free to search relevant literature on the web), one crucial part should be discussed in a nutshell nevertheless: the “Resource Description Framework” (RDF).
RDF is a datamodel for objects (so-called “resources”) and relations between them and provides simple semantics for this datamodel. The idea behind RDF is to make “statements” about resources. Each such RDF statement consists of a subject, a predicate and an object: the subject names the resource being described, the predicate what property of the resource is going to be described and last but not least, the object holds the value of this property itself. This combination is known as RDF “triple”. For example, the sentence “the sky is blue” can be expressed as an RDF statement or triple – with “the sky” as subject, “is” as predicate and “blue” as the object. It is important to note, that RDF names especially subjects and predicates not arbitrarily and freely, but uses URIs instead for referencing things in a globally unique and consistent way. Such things can be resources or real-world objects, respectively, like a place or a book, but also abstract concepts, like relationships between those resources. URIs are used to reference those actually meant things in an abstract, but also machine-readable way. Additionally, an object can be a literal (like “blue” in “the sky is blue”), but also a URI itself, referencing other resources (like “Peter” in “Paul knows Peter”, assuming that “Peter” is a resource which is described further in additional statements).
All in all, such RDF triples form intrinsically a labelled, unidirectional multigraph. In other words, RDF’s subjects, predicates and objects can be represented graphically; with subjects and objects as nodes and predicates as directed edges – all of them labelled accordingly with URIs and/or literals. Such an RDF graph can have multiple, distinct edges between two nodes, whereas these two nodes do not necessarily have to be distinct as well. The later type of graph is also called a “multigraph”.
By convention, resources are represented in illustrated RDF graphs as ellipses, in contrast to literals, which are normally depicted as rectangles. So, they are easily distinguishable. Below such an exemplary RDF graph is depicted, illustrating the main concepts of RDF just explained.

Of course, there is much more to learn about RDF and overlying technologies. However, for the sake of the discussion at this point the explanations up to now should prove to be sufficient. Anyway, in order to understand how the budgetary data is modelled in this very project, its composition and used RDF vocabulary needs to be explained as well.
Most of the statistical data (as well as the budgetary data on this website) is nowadays organised digitally in multi-dimensional so-called “data cubes”. The primary features of such a (three dimensional and simple) data cube are illustrated in the picture below.
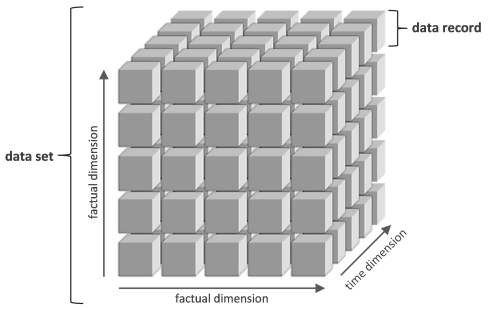
An arbitrary data set originating the same thematic area composes a data cube with a virtually unlimited number of individual data records comprising its elements. Each and every data record itself consists of various attributes and one or more measurands. The record can be located or, to be more precise, is identified by an explicit number of its attributes or key indices. Each combination of these indices is unique for every data record in the cube (e.g. the time and place the data was recorded and so on). Like the three variables x, y and z are normally used to identify any point in a three-dimensional space, the mentioned indices identify every data record in the cube unambiguously and are called likewise dimensions.
The advantage of organising data in this – of course – more complex way (in comparison e.g. with classical two dimensional spreadsheets) is – among other things – that reality can be modelled and, as a consequence, described in a more correct and fine-grained way. The data itself as well as analytics based on it are able to be much more meaningful, informative and, if nothing else, more detailed. Of course, this more complex method needs more attention during modelling in order to work as intended.
For this purpose, the so-called “RDF Data Cube Vocabulary” is used explicitly for modelling the vocabulary for local government finances in Austria and respective data. This Data Cube vocabulary is primarily focused on the publication of multi-dimensional data as Linked Data. The actual, overall structure of the “RDF Data Cube Vocabulary” is depicted below.
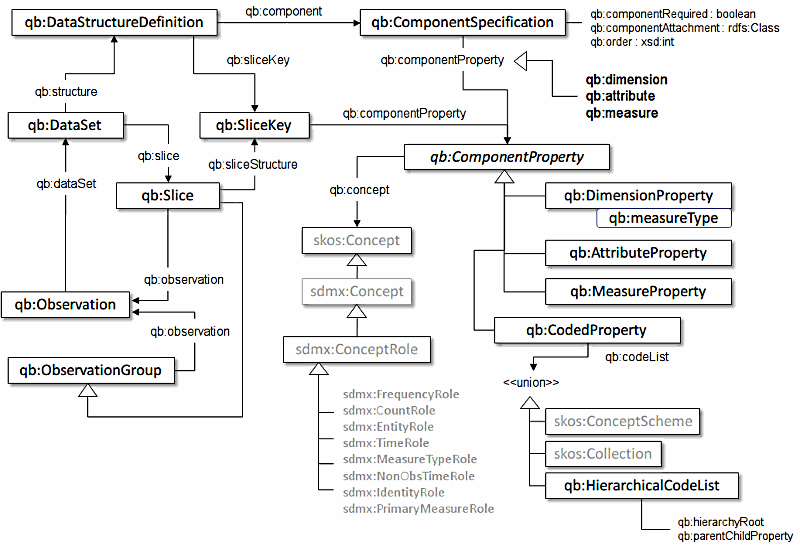
The heart of this project’s application of this RDF vocabulary is – illustrated in the upper left corner – a data set and its respective data set definition. Whether these concepts are used correctly – hence, whether a so-called “well-formed” data cube was created – is answered by reviewing certain predefined “integrity constraints” – for the matter of this project this is done on this page. However, for more information on these concepts in particular and this meta-vocabulary in general, please refer to its specification by the World Wide Web Consortium.
↿ Back to top ↾Open Data
Last but not least, the disclosure of digital data in general or its result, respectively, is commonly known as “Open Data” – eponymous for the title of this project's website. The idea of Open Data’s concept is not new. It originates for digital contents from the idea of “Open Source” software, whose source code is freely available for everyone. The reason for creating such “Open Source” software in the first place was that developers did not want to start from scratch each time implementing a new application. Instead, there was a certain need to build upon source code by others – if possible, without any (commercial or legal) hurdles. With Open Data, the footsteps of “Open Source” software shall be followed for digital data in general, possibly achieving similar popularity as its forefather.
While the general concept of Open Data in particular seem to be quite obvious at first glance, an explicit definition is not that easy. One of the commonly adopted definitions is the “Open Definition” by Open Knowledge International. It describes Open Data as information that can be freely accessed, used, modified, and shared by anyone for any purpose (subject, at most, to requirements that preserve provenance and openness).
Of course, the legal aspects of such Open Data are manifold. However, they are not tackled on this website in particular. However, it shall be noted that respective licensing is also used by this project. For more information about legislation on Open Data as well as the respective licenses, please refer to the underlying Diploma Thesis of this project.
Linked Data, which is released under an open licence, which – in turn – does not impede its reuse for free, is called “Linked Open Data” (LOD). The latter concept describes – at its best – structured, highly interconnected and syntactic interoperable information or datasets, respectively, which are distributed over various data sources and repositories (like this project’s SPARQL endpoint) within the same or different organisation and can be used by everyone without any restrictions. As a consequence, LOD is an important mechanism for information management and integration; hence, in turn, it becomes more and more important in state-of-the-art implementations of data interfaces and storages for Internet-based services and applications. In this way, data is not just published somewhere on the World Wide Web, but instead in the Web by using LOD; this way, the goal to achieve a real & infinite Web of Data – additionally, to a Web of Documents – moves a little bit closer.
Representing that this process is more a progressive, stepwise transition rather than an encompassing adoption in one go, famous Tim Berners-Lee introduced a so-called “5-Star-Scheme” for Linked Open Data. As depicted below, it classifies published datasets from protected, not reusable content (without any star) through to real LOD composing an open Web of Data (gaining a total of five stars).
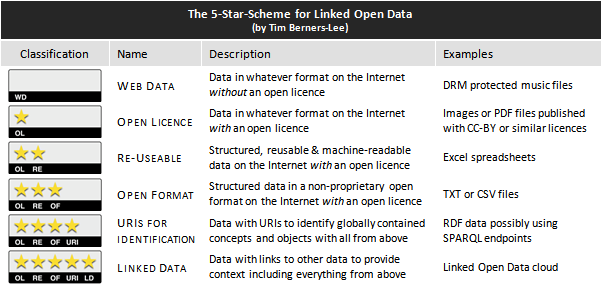
As shown in detail, by this project’s underlying Diploma Thesis, the Linked Open Budget Data as well as its respective vocabulary for local government finances for Austrian municipalities is compliant to 5-star-LOD: the available information is modelled as non-proprietary, machine-readable and structured RDF data, where dereferenceable URIs are used to identify given concepts as well as the data records themselves. These URIs conform to overall requirements of Linked Data. Furthermore, even Linked Data outside the dataset’s namespace is referenced (e.g. for identification of municipalities). With that the given project reaches full-blown, encompassing and comprehensive Linked Open Budget Data for Austrian municipalities and provides an unprecedented contribution to the evolving Web of Data in Austria in the end.
On this page, all used figures are made for the purposes of this website itself – except the overview of the “RDF Data Cube Vocabulary”, which was originally created by the W3C, and the LOD star badges by Richard Cyganiak. All figures can be used – as all other parts of this website – freely under the CC-BY license.
How much data is stored here?
- 3municipalities
- 14fiscal years
- 80,419data records
Which Diploma Thesis is this?
This website was originally developed and published in the year 2017 as part of a Diploma Thesis in fulfilment of the requirements of the Master Programme in Business Informatics at the Faculty of Informatics of the Vienna University of Technology. Of course, it is publicly available for everyone to gain further inside in this topic as well as the implemented approach shown with this project.
Show me how I can get this Diploma ThesisHow to get this Diploma Thesis...

As a single point of contact, the Diploma Thesis serving as a foundation for this project’s website is hosted by the Vienna University of Technology or its University Library, respectively. In this way the publication is archived, provided with a persistent identifier, so that it can be reliably & consistently referenced, and made available online all over the globe for use in accordance with applicable copyright law.
The actual document is available via the button below in its PDF version only and can be used freely by anyone without any restrictions as all scientific works on Austrian Universities. For more information on the document and the work itself, please have a look at the respective page on the website of the University Library.
DownloadWhich technologies are used here?
This project’s website uses a variety of different technologies as well as third-party applications, which are open source, for implementing Linked Open Data in an appropriate, sophisticated way. Of course, all used components are documented on this website as well as the terms under which they are used and their respective source.
Learn more about these used technologies